gender <- c("男", "女", "男")
gender <- as.factor(gender)データフレーム
ファクター
統計データにおいて分析の対象となる変数は,概ね数値型かカテゴリ型かのいずれかである。たとえば,身長や体重は数値であり,性別,居住都道府県,質問に対する回答が「はい」か「いいえ」か,などはカテゴリである。
カテゴリを扱うには,factor型ベクトルを用いる。たとえば,「男」と「女」のいずれかを格納するベクトルgenderを作成し,factor型に変換してみよう。ベクトルをfactor型に変換するにはas.factor()関数を用いる。
genderの内容を確認してみよう。
gender[1] 男 女 男
Levels: 女 男これは,ベクトルの内容は3人の性別(男,女,男)で,ベクトルの要素は「女」と「男」の2つのレベルに分類されていることを示している。
factor型のオブジェクトは,数値型へと変換することができる。factor型のオブジェクトgenderを数値型に変換して,新しいオブジェクトgender_numに代入してみよう。
gender_num <- as.numeric(gender)
gender_num[1] 2 1 2性別が番号(女: 1,男: 2)に変換されていることがわかる。このとき振られる番号は,Levelsで表示される順番となる。レベルの順番は,factor()関数でlevelsを指定することで変更可能。
gender <- factor(gender, levels = c("男", "女"))
gender[1] 男 女 男
Levels: 男 女as.numeric(gender)[1] 1 2 1データフレーム
多くの場合,統計データはデータ・フレームの形に整理して分析する。データフレームは複数のベクトルを束ねたものであり,観測単位 (個体や時点)ごとに変数が記録されたデータ構造である。たとえば,3人の名前が格納された変数name (文字列型),年齢が格納された変数age (数値型),性別が格納された変数gender (factor型)を,1つに束ねてdfというデータフレーム・オブジェクトを作成してみよう。データフレームを作成するには,data.frame()関数を用いる。data.frame()関数の引数には,データフレームに含めたいオブジェクト(ベクトル)をカンマで区切って指定する。
name <- c(
"大阪 太郎",
"兵庫 次郎",
"京都 花子"
)
age <- c(
19,
21,
20
)
gender <- factor(
c(
"男",
"男",
"女"
)
)
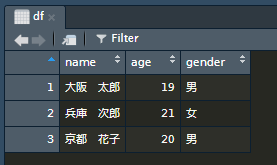
df <- data.frame(name, age, gender)
df name age gender
1 大阪 太郎 19 男
2 兵庫 次郎 21 男
3 京都 花子 20 女行数3 (3人分のデータ),列数3(name,age,genderの3つのベクトル)のデータフレームが作成されたことが確認できる。
Environmentタブにもdfが追加されていることを確認しよう。データフレームの中身を確認したいときには,EnvironmentタブはList表示にしておく方が便利。データフレーム名の左にある青い矢印のようなボタンを押せば,内容の表示・非表示が切り替えられる。
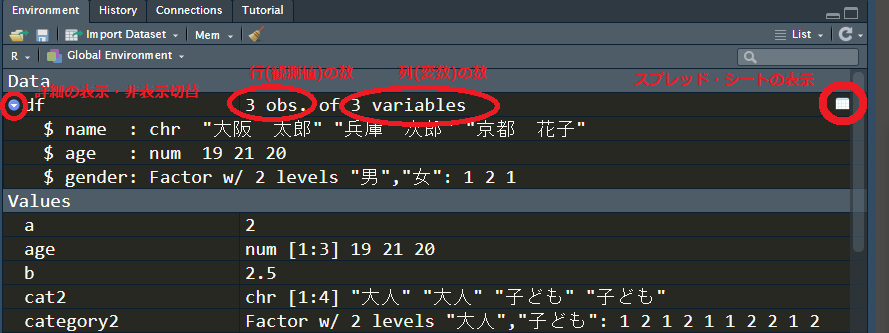
データフレーム名 (いまの場合はdf)もしくはその右にあるスプレッド・シートのマークをクリックすれば,ソースコードのペインにデータフレームがExcelのようなスプレッド・シート形式で表示される (並替えやフィルターなどの操作が可能だが,内容の編集はできない)。
データフレームに含まれる変数は,データフレーム名$変数名で表す。たとえば,dfというデータフレームのageという変数であれば,df$ageで表す。
たとえば,3人の平均年齢を求めてみよう。
mean(df$age)[1] 20
data.frameとtibble
data.frameは,Rの基本パッケージだけで利用できるオブジェクトの型である。現在はtibbleパッケージ (tidyverseに含まれる)を読み込むことで利用できるtibbleという型が,data.frameの上位互換として良く用いられる。
データの読込み
csvファイルの読込み
統計データを分析する際には,csvファイルやExcelファイルなどのデータをデータフレームの形で読み込むことが多いだろう。たとえば,“data.csv”というcsvファイルをdfというデータフレームの形で読み込むには,read.csv()関数を用いる。
df <- read.csv("data.csv")csvファイルは,1行目にヘッダー (変数名)が記載された形にしておく。ヘッダーがない場合には,header = FALSEという引数を追加すれば読み込める。
Windowsで作成したcsvファイルをRに読み込む場合には,ファイルのエンコーディングに注意が必要である。UTF-8で保存すれば問題ないが,エンコーディングがShift-JISの場合には,read.csv()関数の引数にfileEncoding = "Shift-JIS"を追加すれば読み込める。
ファイルからデータを読み込んだ場合,各列 (変数)の型は,データの内容に応じて自動的に決定される。このとき,数値として扱いたいデータが文字列になっている場合があるので,正しい型になっているかどうか確認しておこう。
また,文字列型のデータを自動的にfactor型に変換して読み込むこともできる。この場合には,stringsAsFactors = TRUEという引数を追加すれば良い。
欠損値の処理
統計データには欠損値が含まれる場合がある。Rでは欠損値をNAで表すが,ファイルからデータを読み込む場合には,そのファイルで欠損値がどのように記録されているかに注意しよう。欠損値の部分が空欄になっている場合には読み込む際にNAに変換されるが,999などで欠損値を表しているデータもある。その場合は,読み込んだ後でNAに変換しておこう。たとえば,データフレームdfで999をNAに変換するには,以下のようにする。
df[df == 999] <- NA